Now is the time .... maybe
Right now in 2017 its fair to say that machine learning A.I. is arguable the hottest topic in the world of technology and computing. Some of the biggest companies to the most innovative start ups are investing heavily in A.I and already are seeing the benefits, for example google have been able to reduce the amount of energy their data centres consume (about 40% reduction) by enabling deep mind A.I Neural Nets, to manage power flow - by being predictive rather than reactive to demand.
To be clear these new A.I can do more than manage power.. A LOT MORE. Unlike previous tailored algorithms, new breed A.I. are not limited to niche tasks, adoption is rapidly spreading in manufacturing, medicine, research, finance and banking. Even if technological progress was to run to a complete halt today, A.I is still in the embryonic stages of rolling out to the mainstream, when it does it will have seismic effects around the globe and prove disruptive in all fields - and that is putting it lightly.
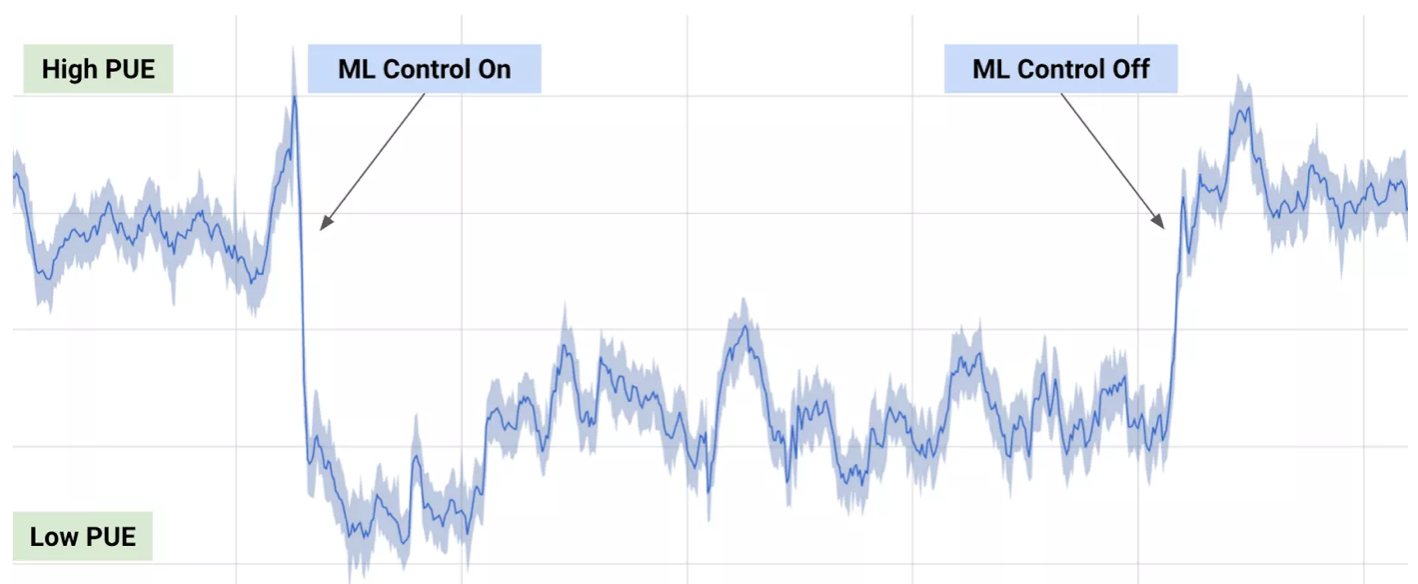
Snapshot of google's datacenter power output when AI management is switched on and off
Andrew Ng, professor at Stanford University and chief scientist at Baidu Research has said “A.I is the new electricity”. Since we are on the hype train, lets take a moment to consider the following.
Neural Networks represent the most recent block added to the A.I pyramid, and are responsible for driving both the renewed and almost psychotic like hype in A.I as well as solving problems that have either eluded specialists for decades or were just considered impossible.
Yet whilst Neural Networks (NNs) are arguably the pinnacle of A.I. progress, they are only good at learning and mastering a certain field. Such as self driving cars, chat bots and predicting the weather. We are still a long way away from Artificial General Intelligence (AGI) - that is being able to apply learning gained in one subject to another completely different subject. If a computer is able to learn how to talk to a human like Siri, drive a car independently and then use these learnings to say teach someone verbally how to drive a car - this would represent the holy grail in machine learning.
Chapter 2
Moving towards A General Purpose A.I
The Differentiable Neural Computer model came from deep mind a few months ago, and is the successor to the Turing machine. This is a relatively complex model but fear not, I will do my best to break it down into digestible parts. The core problem faced by the deep learning team is how to create a more general purpose learning machine - and that is the pretext for building this model.
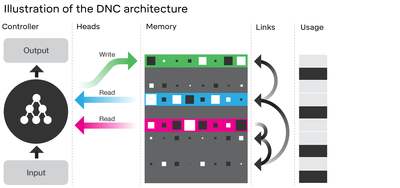 The far left represents a standard neural network, from the heads column moving to the right - represents the external memory which is the key difference from other neural Network architectures.
The far left represents a standard neural network, from the heads column moving to the right - represents the external memory which is the key difference from other neural Network architectures.The problem with neural networks are that they are made to focus on a single task or whatever you train it on. You can’t use the same neural network that learned to recognise music to learn to navigate say the London Underground.
The DNN is a neural network with an external memory store, so it has two parts - the controller which is normal NN , like a feed forward net or a recurrent net or anyone you want. Then you have the memory bank, which is an external matrix, the controller interacts with the memory bank using heads which is read write operations. Takes an input, propagates it through the network, and simultaneously writes to the matrix to both write what it learned and read from the past time steps to look for useful info to help it with its prediction.
Then they added a question answering system, natural language was added. Not only did they train it on the London Underground path, they added natural language. They trained it first on randomly generated graphs then on a text database which was a question answer database. Then associated both, so then you could ask it “hey what’s the best way to get from point A to B , because it had this external memory story which had the previous learning graphs it was able to apply those.
It learned to optimise for one data set, then another and associate the two. This was a text database, it learned to associate questions with answers, then associate that to the london underground map. This is because it had the external memory store which allowed it to apply the map problem to the spoken questions.
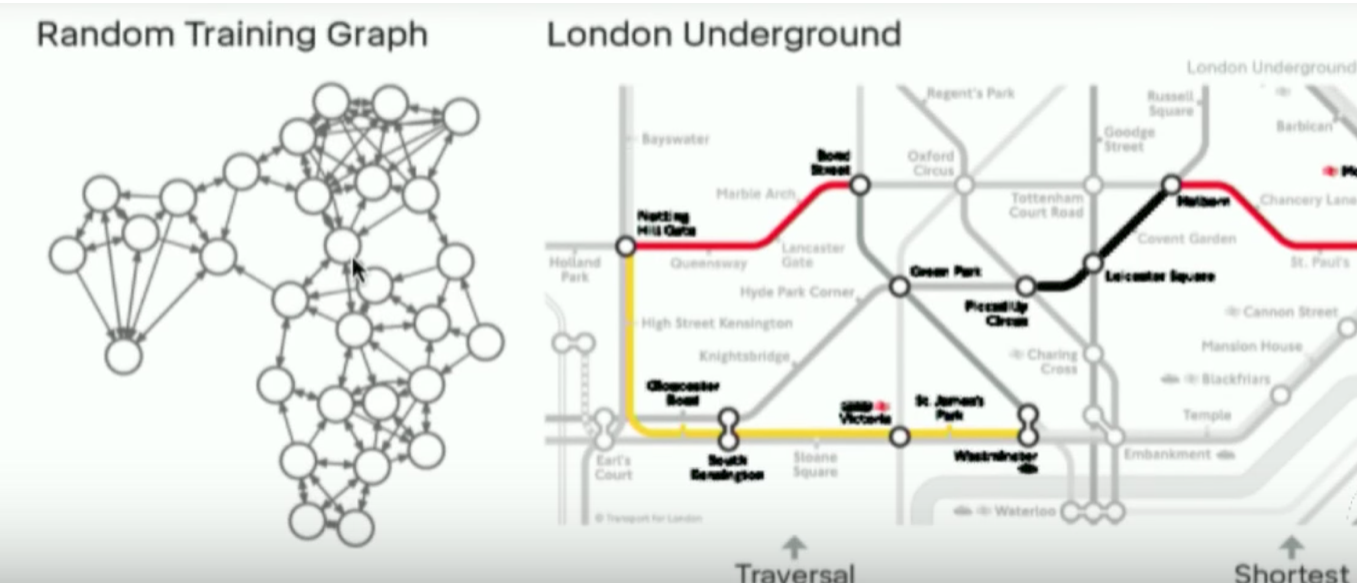
In theory you could apply this to anything such as a subset of images with their labels, then something entirely unrelated. So you could ask, what kind of sound could this cat make it looks at the cat then sound files. It is not perfect nor is it AGI, but its a step in the right direction. It is called a computer because a standard computer has a processor and memory, at the kernel level anytime you perform actions the RAM preloads instructions which is fed to the CPU that takes the instructions, decodes it then executes it one step at a time and repeats the process. This process is called the instruction cycle, that is Von Neuman architecture and is the hall mark of computational science. GPUs are a different story and will be covered later.
This may also be a framework for also building hardware, “ if we switch our thinking from serially decoding instructions, to instead learning from instructions at the kernel/hardware level we could produce some interesting results”. There are people working on this, but it will be inspiring to think about the successor of to the Von Neuman architecture and Silicon medium for computing.
More DNC Applications
Another example of deep mind’s practical implementation by associating two different data types was with understanding complex family tree relations. They first fed it some associations with text descriptions as shown in the video below.
Layers of complexity were added incrementally, adding more branches to the family tree.
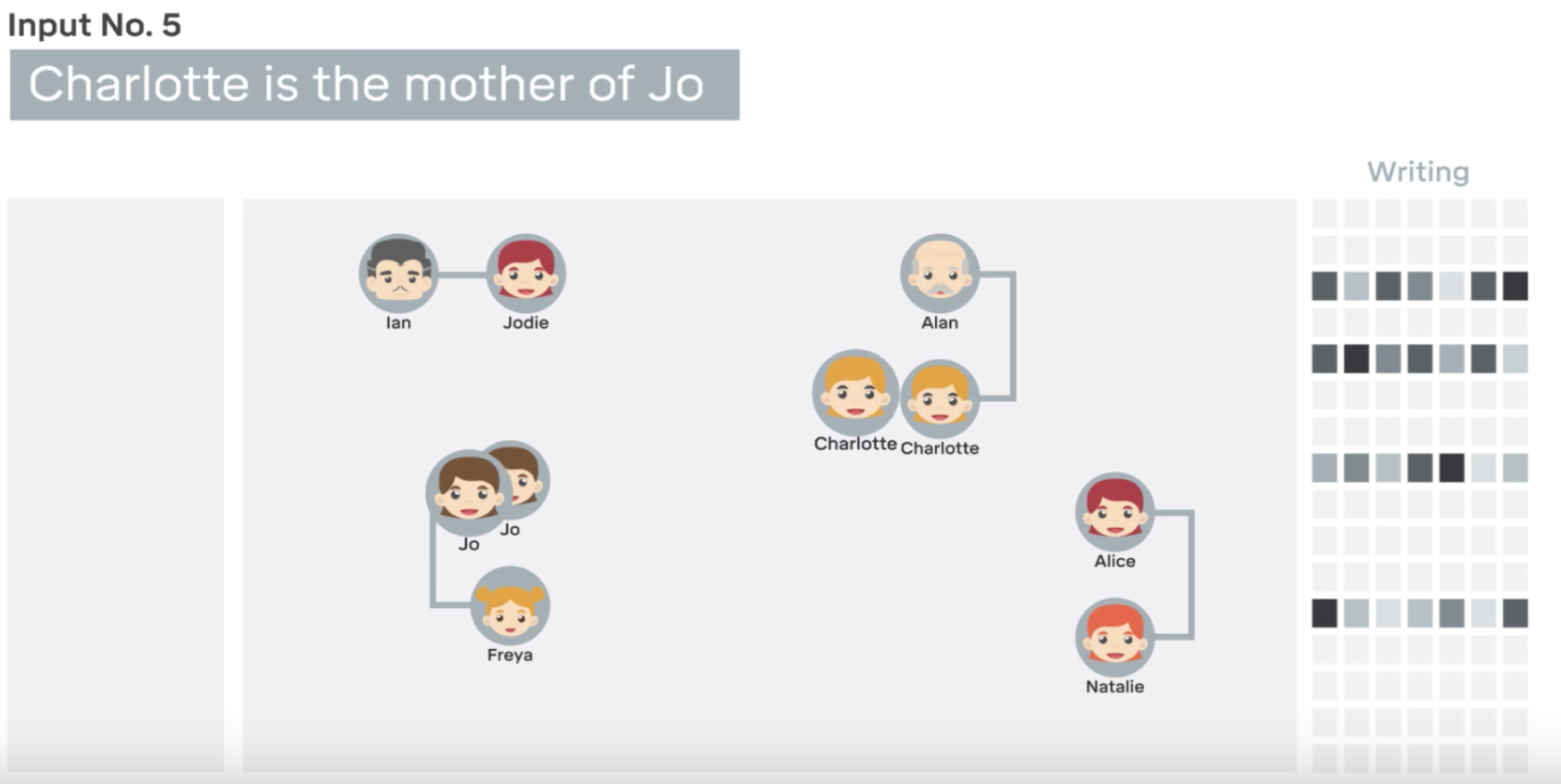
These were a group of Natural language text associations. But, then after building up the tree, you could ask a TEXT QUESTION which related to an unspecified connection i.e. when building up the tree, there were only a certain number of connections mentioned i.e. Charlotte is the mother of Jo, but we did not say explicitly who is Freya’s maternal great uncle.
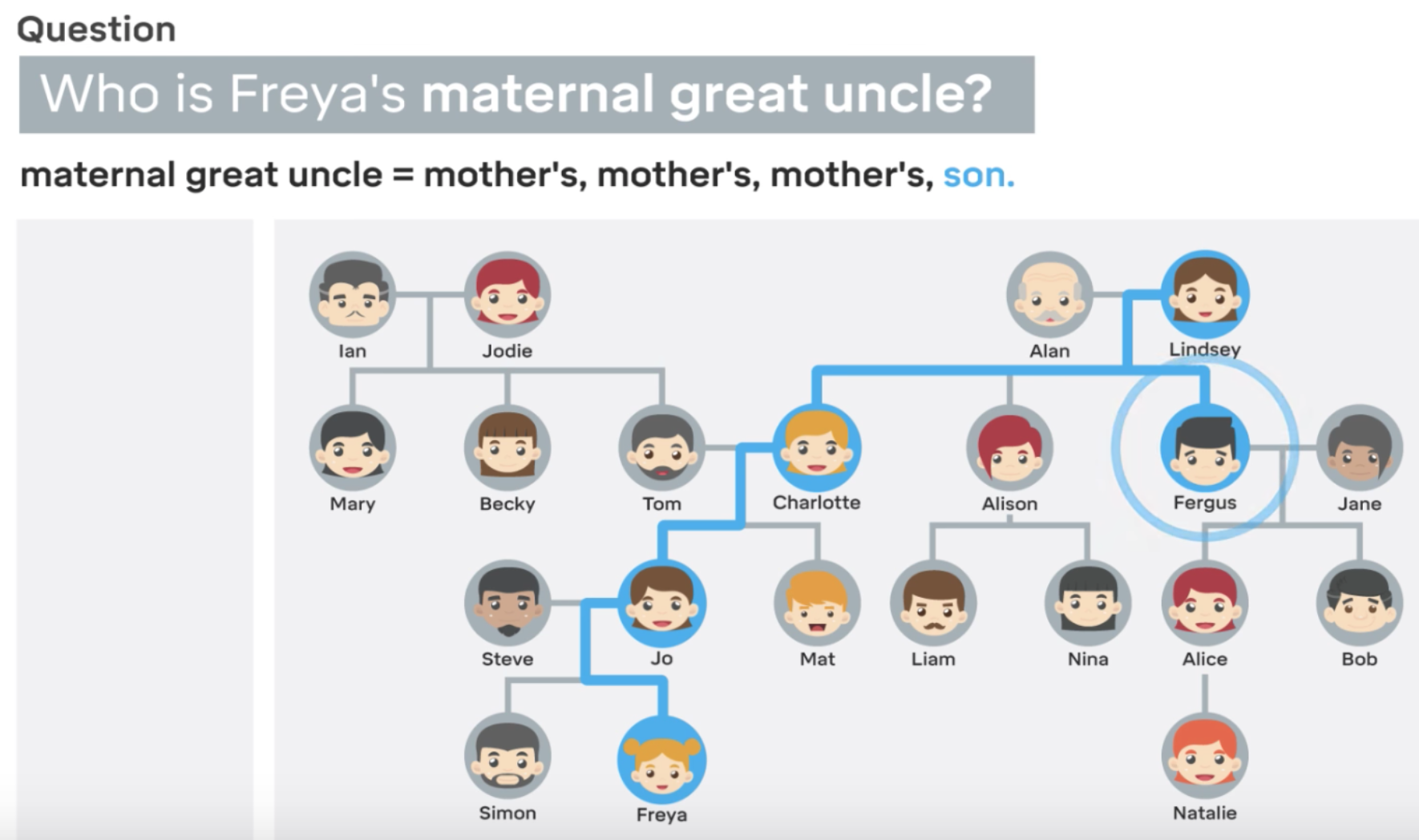
When asking this question, it was able to use the optimised graph solution, but also using the optimised natural language solution together. Normally this wouldn't to be possible by any conventional machine learning algorithm or neural network. if you have seen something like Siri where someone asks a question similar, what is actually happening is simply an internet search. The possibilities for tying together two neural networks in a way they can learn from each other holds many great possibilities in store.
So using an external memory store sounds like a simple concept, but had never been fully implemented, Facebook did have dynamic memory network and there was also the neural Turing machine but the DNC has been the first successful implementation.
Whilst you may say, “wait a minute neural networks already have memory” - this is true but the memory acts as the weights and is interpolated so tightly with the processing But having the memory detached allows for magical results.
Further Reading
- The Differentiable Neural Computer - DeepMind
- Google's Deepmind Data Center Cooling
- Siraj Raval - full DNC walkthrough

Many thanks for reading, please like or share below if you want to see more.
Adam McMurchie 28/May/2017
